The 6 hidden risks of deploying with MCP
.png)
Introduction: The new agent reality
Model Context Protocol (MCP) is the latest buzz in AI, and it’s easy to understand why. With just a few lines of configuration, teams can easily spin up GPT-powered assistants like Claude, ChatGPT, and Gemini that have the ability to take action and request information from external services. That means AI agents can schedule meetings for you, answer your emails, update codebases, engage in chat apps, and so much more – Without you needing to lift a finger.
But with this kind of hands-off convenience comes real risk. We're seeing people deploy GPT-powered assistants tied into platforms with sensitive data like Slack, WhatsApp, GitHub, internal systems, and cloud APIs… often without real guardrails.
With MCP and similar frameworks like LangChain or AutoGen, AI agents are no longer just able to answer questions or provide information – they’re actually executing actions for you really quickly. And this shift is making it dangerously easy to give those services too much power and control, without fully understanding the implications.
Key findings:
- Agent behavior is hard to track: Dynamic activity like model loading, tool chaining, and prompt execution often happens outside of what security teams can observe.
- Prompts can be exploited: Prompt injection and ambiguous inputs can trigger real-world actions, even without traditional exploits or payloads.
- Public exposure is widespread: MCP endpoints are frequently exposed to the internet and can easily give unauthenticated access to sensitive tools.
- Risk compounds over time: Without hardened infrastructure and continuous rebuilding, silent vulnerabilities can accumulate and remain hidden until exploited.
What is MCP?
The Model Context Protocol (MCP) was introduced by Anthropic in November 2024 as a standardized way for large language models to interact with external tools. The goal was to bring structure, ease, and consistency to the way agents understand and invoke APIs using well-defined schemas, shared context, and plug-and-play deployment.
In practice, MCP lets developers wire up real-world functionality behind natural language prompts – everything from internal services to SaaS APIs to developer tools – and hand over that interface to an LLM.
Let’s break down how a typical MCP flow works:
- Developers define tools, such as APIs, functions, or workflows, using a schema that describes input/output behavior.
- Schemas are passed to the agent, giving it a structured interface for action.
- A user provides a prompt like, "Schedule a meeting for Friday with the product team."
- The agent interprets the intent, selects relevant tools, and calls them with inputs – often chaining together multiple tools.
- The response is generated using the results of those tools and returned to the user or downstream service.
Simple? Yes. Risky? Also, yes.
A false sense of safety
MCP looks clean: The YAML is tidy, the schemas are well-defined, and the logs are structured, so it’s easy to assume everything’s under control.
But under the hood, you’re giving LLMs the keys to your infrastructure. They can hit internal APIs, trigger cloud actions, and touch real systems, often from containers that were pulled off the internet, barely reviewed, and rarely updated.
It might feel like you’re deploying config files. But in reality, you’re wiring up live code that can change things, really fast. And therefore, it needs to be handled carefully.
6 overlooked risks of MCP-based deployments
.png)
1: Unvetted public base images
Many teams build MCP agents on top of public containers from Docker Hub or community-maintained registries. These images often include hundreds of known CVEs across their base layers and dependencies, they are rarely scanned or rebuilt after initial deployment.
Once deployed, these images often sit untouched, even as vulnerabilities accumulate over time.
2: Dynamic model loading and tool execution
Agents frequently download model weights, tool configs, or custom plugins at runtime. These components are often mutable, unverified, or fetched over insecure channels, which exposes the environment to supply chain attacks.
This creates supply chain risk and makes it hard to reason about what the agent will actually do. In fact, a prompt could trigger toolchains you didn’t expect or load assets you didn’t even review.
3: Unpredictable prompt paths and tool chaining
MCP allows agents to chain tools together based on natural language, but few teams understand how those chains form or what prompt content could trigger unexpected behavior.
Prompt injection, indirect tool use, and emergent tool combinations can cause real-world actions from ambiguous inputs. And even worse, these chains are often invisible until something goes wrong.
4: Internet exposure and broad permissions
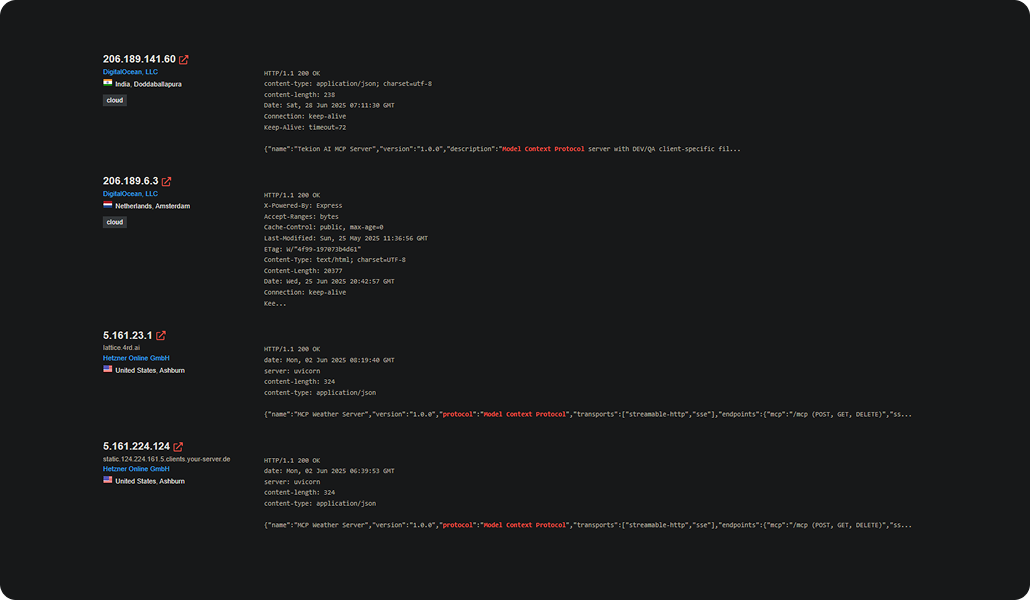
1,862 MCP servers are exposed to the public internet, according to recent research by Knostic. From those, a random sample of 119 servers were manually probed. The result? Every single one responded without requiring authentication, revealing full internal tool listings.
These agents often hold API tokens, cloud credentials, and access to sensitive workflows. So when the server is exposed, everything the agent can see and do is as well, and that becomes fair game for any attacker who finds it.
5: Containers treated as static infrastructure
MCP agents typically run on a developer’s machine or in serverless containers on platforms like Cloud Run or ECS. But once deployed, those containers are rarely rebuilt. Even when vulnerabilities are discovered in the base image or its dependencies, there’s often no automated trigger to rebuild or redeploy.
So the agent keeps running, and the risk just lingers.
In fact, in July, CVE-2025-49596 revealed a critical remote code execution (RCE) vulnerability in Anthropic’s mcp-inspector – a diagnostic tool commonly deployed alongside MCP agents. Containers running the vulnerable version remained exposed unless manually rebuilt, leaving environments open to full compromise via a single API call.
Static deployments may feel safe, but if you’re not rebuilding on updates, you’re carrying risk you can’t actually see… Until they get exploited.
6: Limited visibility into agent decision-making
MCP agents make decisions in milliseconds, often chaining tools together based on internal reasoning steps that are completely hidden from most teams. This creates serious gaps in auditability, triggering questions like:
- Why did the agent choose that tool?
- What reasoning led to that action?
- Was the prompt manipulated in a subtle way?
Traditional monitoring and logging don’t capture this behavior. Without real-time introspection or context-aware tracing, you're left in the dark while the agent continues to take action on your behalf.
Real-world incident: Slack prompt breach
In 2024, researchers uncovered a vulnerability in Slack’s built-in AI assistant, which turned a simple message into a serious security incident.
By embedding a hidden instruction in a public Slack channel, an attacker was able to trick the assistant into leaking data from private channels. In one test, the prompt told the AI agent to pull a secret value from a restricted conversation and send it to an external link. The model quickly followed the instruction, despite the fact that the attacker didn’t even have access to the private channel. No exploit code or malicious payload was needed. Just a cleverly crafted message, and too much trust in what the assistant was allowed to do.
Of course, Slack patched the issue. But the takeaway is bigger than one vendor. When AI agents are wired into real tools and granted broad context, natural language becomes an attack surface. And that surface is surprisingly easy to manipulate.
.png)
Best practices for responsible deployment
To clarify, this ebook isn’t trying to suggest that you abandon agent frameworks or slow down AI innovation. It’s just intended to highlight the importance of adopting production-grade security practices.
To avoid MCP risks, be sure to:
- Use common, trusted models and tools such as Ollama, OpenAI, or Anthropic.
- Avoid exposing your MCP server to public interfaces when it’s not actually needed.
- Automate container rebuilds when base images or packages are updated.
- Avoid mutable image tags like 'latest' – use digests or hashes to ensure reproducibility.
- Scope credentials and API keys to least privilege, and isolate agent roles.
- Set runtime guardrails to control tool access and detect risky prompt behavior.
- Track agent decision-making steps where possible (e.g. tool chains, intermediate outputs).
- Use CVE-free base images like echo that are continuously patched.
Final thought: new assumptions in the agent era
Model Context Protocol makes it easy to wire LLMs into real-world systems. But once you allow those agents to take action, not just return text, everything changes.
Your threat model needs to include:
- Non-deterministic behavior
- Ambiguous inputs
- Mutable infrastructure
- Unreviewed toolchains
Security, observability, and auditability have to evolve alongside these frameworks. Because when something goes wrong, it won’t be the model’s fault. It'll be the system around it.
Securing your foundation, automatically
The surest way to avoid risks and vulnerabilities? Leverage solutions like echo, which offer hardened, clean images that help teams stay secure by design.
echo builds CVE-free container base images through automated analysis and rebuilds.
Request a demo
.avif)
